The main bottleneck of creating distributed RL algorithms is that we need to create our own datasets with improved policies. Unlike SL where the datasets are given. This means we need to create algorithmic changes alongside system changes when designing new parallel architectures.
History of large scale distributed RL
2013. Original DQN
DQN parallelisation was not DeepMinds main focus when first presented in 2013. Nevertheless, understanding its implementation helps to get an idea of how the others work. If you need a reminder, take a look at lecture 8.
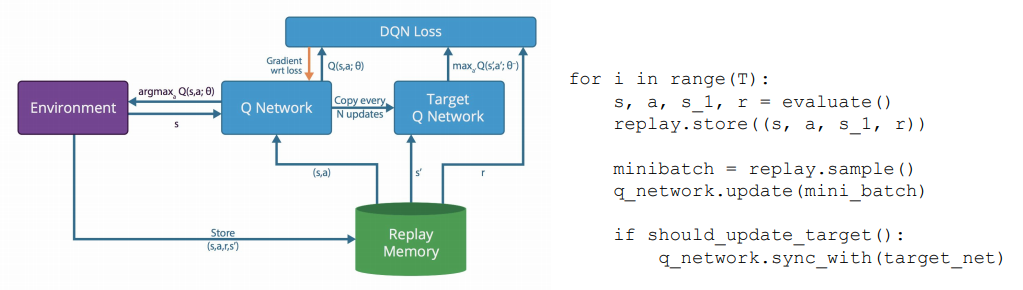
DQN algorithm basic structure.
2015. General Reinforcement Learning Architecture (GORILA)
This paper has a lot of margin of improvement but was the first distributed approach taken. They split the algorithm into 4 components to be replicated and run on multiple nodes:
- The replay buffer/memory: Stores \((s, a, r, s^\prime)\) samples from the environment.
- The learner: Pulls data from the replay memory and updates the Q networks.
- The actor: Gets a copy of the policy network and provides \((s, a, r, s^\prime)\) samples to the memory buffer.
- The parameter server: Holds a copy of the Q network and allows the learner to update the network at very high throughput.
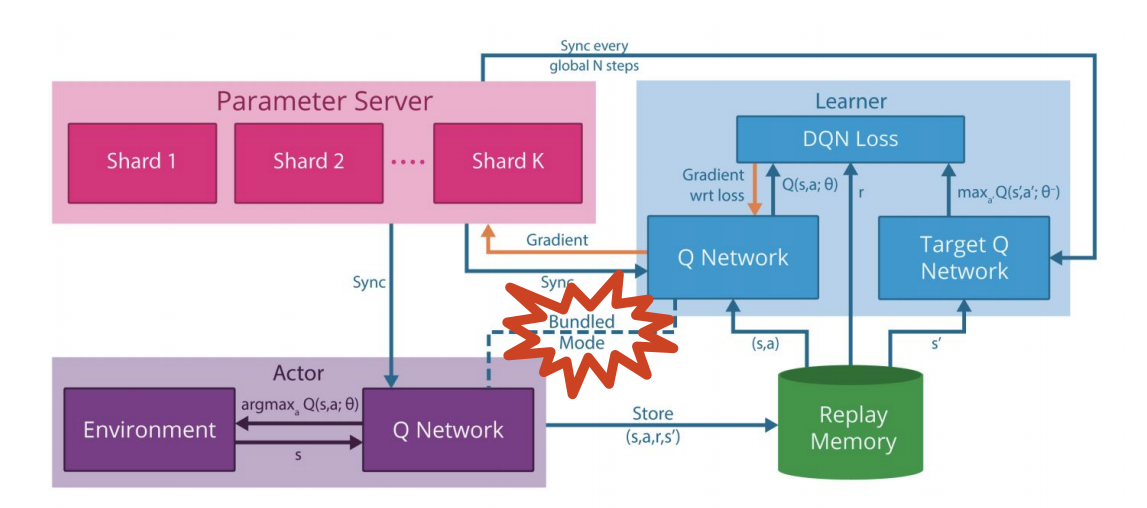
GORILA distributed architecture structure.
Bottleneck: The way they implemented it, they only sample from the actors one step and then update the networks. This makes the data generation pace to be too slow: They update the network too frequently and sample from the environment too infrequently.
Still, this approach outperformed most Atari games benchmarks set by the original DQN paper.
2016. Asynchronous Advantage Actor Critic (A3C)
While not significantly different from the previous one, this was one of the most influential works on efficient RL. The main difference is that it runs on a single machine, which allows us to mitigate the network communication overhead. Thus, deprecate the replay buffer and use an on-policy training and compute gradient with the steps each worker generates and not from random times.
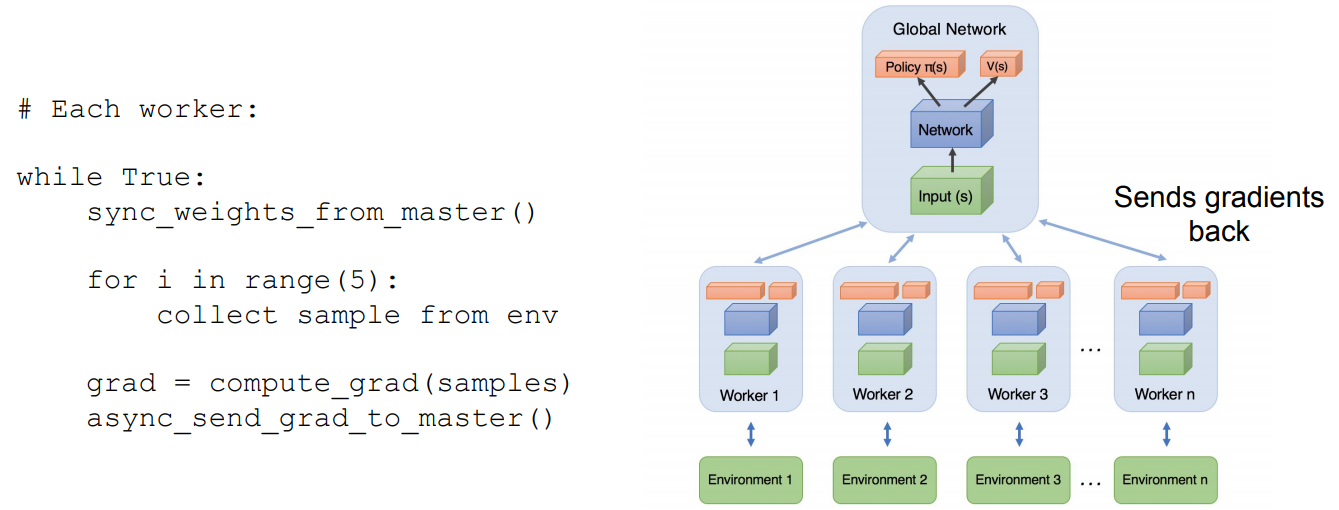
A3C structure.
All workers has access to a global set of weights stored in shared memory (master process). For each iteration they update their own weights from the master ones. Subsequently, we can make each worker collect some samples (e.g. 5) from their copy of the environment and compute the network gradient loss from those. Then, we can take this gradient and send it to the global network to update its weights.
Additionally, this allows us to set different exploration policies to each worker and have a faster learning process. Compared to GORILA, we can increase the rate of update by:
- Reducing network communication by having everything into one machine.
- Compute more experiences before the network update.
This architecture also easied the parallelisation of policy gradient techniques and not only Q-learning which was dominating at that point. Performance-wise it achieves 3 times better results than DQN in less time and machines (see paper for full analysis).
Problem: It does not scale well on the number of actors due to Policy Lag. If you have say 400 actors sequentially updating the global NN, the samples from the last one are going to be so out of date that its parameter update does not make sense any more.
2017. Importance Weighted Actor-Learner Architectures (IMPALA)
IMPALA marges the learnings acquired from distributed Deep Learning and RL. In this case we also lack the data buffer and have the separation of actors and learners:
- Learners: Implement a parallelised gradient descent mechanism to efficiently update the network weights across multiple machines.
- Actors: Can act independently from the learning process and generate samples faster.
In previous approach you first need to generate some data and then wait until the network gets updated, while now this gets decoupled.
Policy Lag Problem: Decoupling acting and learning can make the actors follow policies which are quite older than the latest computed by the learners. This means they produce samples from a different distribution (policy) than the one that will get updated.
Solution: V-trace: weight the network updates inversely proportional to the policy distance which generated them. In the paper, they show how this mitigates the issue.
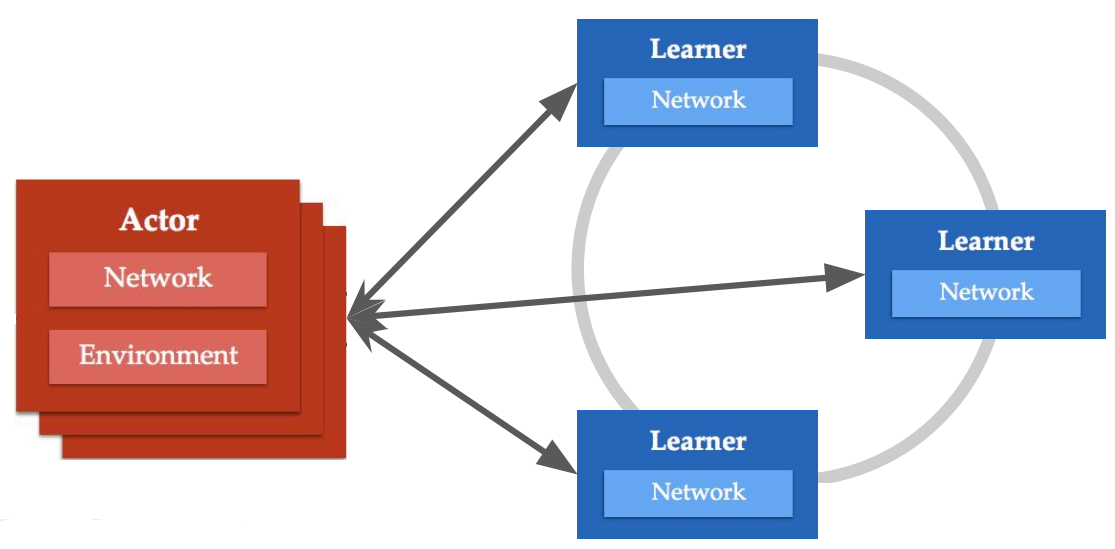
IMPALA structure.
2018. Ape-X / R2D2
This method takes a step back into GORILA and uses again the replay buffer mechanism. Similarly, the actors are separated from the learning process and generate data asynchronously feeding the data points into the replay buffer. This approach is very scalable, you can have multiple actors sampling independently feeding the buffer.
The main novelty of this work is the sorting of the data in the replay buffer using distributed prioritization. This technique works by setting a priority to each data point fed into the buffer. This allows the learner to sample from this scoring distribution which should be designed to facilitate the learning process. For instance you can assign a higher priority to new samples. Once the learner evaluates a point assigns a lower priority so chances it gets re-sampled are lower.
Problem: You end up sampling too much recent data and becomes a bit myopic.
Solution: The same actor ANN assigns priorities avoiding the recency bias.
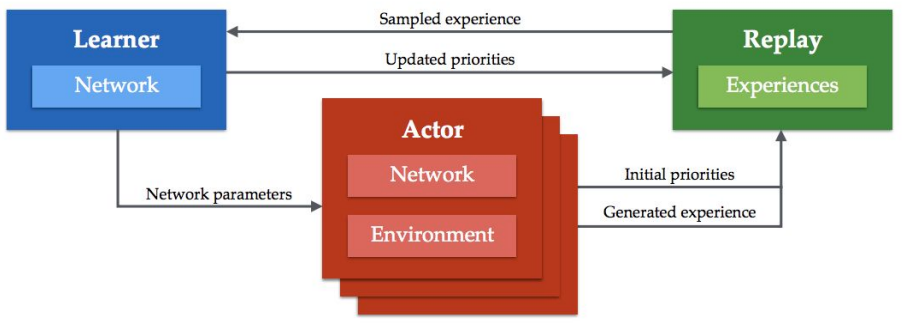
Ape-X architecture.
Performance-wise greatly outperformed all other SOTA algorithms by that time.
OBS: R2D2 (Recurrent Ape-X algorithm) is essentially the same with an LSTM.
2019. Using expert demonstrations R2D3
This algorithm uses both expert demonstrations and agent’s trajectories. It sets some sampling probability to each datapoint depending on its origin.
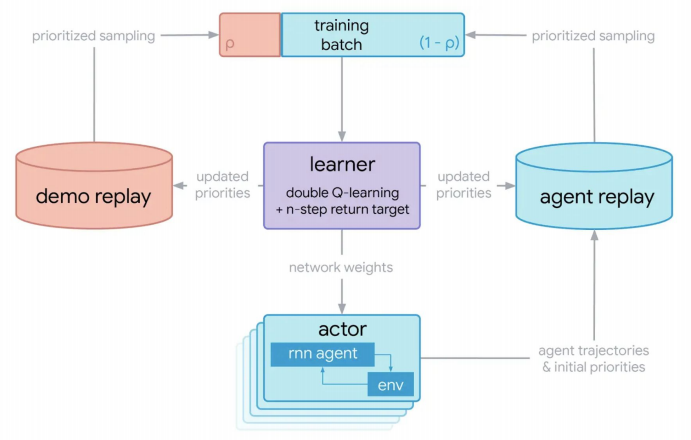
R2D3 architecture.
Others:
QT-Opt
This distributed architecture main feature is that it interfaces with the real world. Moreover, its weight update happens asynchronously. Meaning it can be easily heavily parallelized into multiple cores (can be independently scaled). It was designed for robotic grasping, using a setup of 7 robots creating samples.
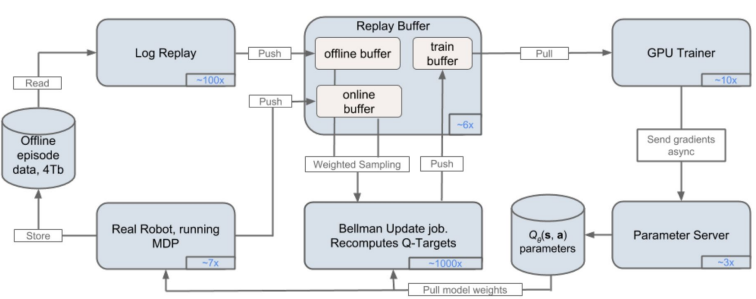
QT-Opt architecture.
Evolution Strategies
Gradient-free approach by OpenAI. Essentially uses an evolutionary algorithm on the ANN weights. It works by having multiple instances of the network where it applies some random noise. The idea is then to run the policies and perform a weighted average parameter update based on the performance of each policy.

Evolution architecture.
Population-based Training
Technique for hyperparameter optimization. Merges the idea of a grid search but instead of the networks training independently, it uses information from the rest of the population to refine the hyperparameters and direct computational resources to models which show promise.
Using this technique one can improve the performance of any hyperparam-dependent algorithm.