Before venturing into the details of Reinforcement Learning, lets take a step back and see the strengths of each type of Machine Learning:
- Supervised Learning: Useful for recognition (classification/regression) of unstructured (labeled) data.
- Unsupervised Learning: Useful for distribution inference, dimensionality reduction, clustering, latent variable inference… of unlabeled data.
- Reinforcement Learning (RL): Useful for decision-making problems: An agent interacts with an environment. It perceives states and takes actions according to some policy to maximize a sense of reward.
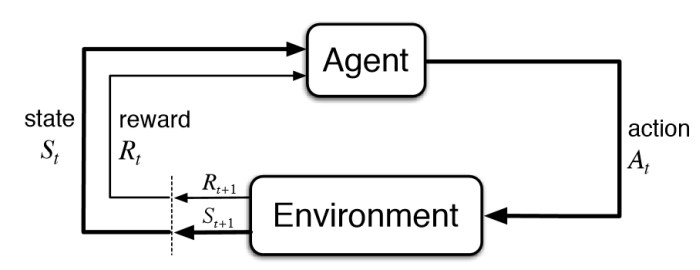
RL problem structure
Most problems we perceive as AI problems can be framed as RL problems. (e.g. Image classification can be seen as a decision problem with +1 reward when correctly classified).
Deep models are what make RL solve complex tasks end-to-end. They allow the direct mapping between states and actions.
Ways to learn:
From expert demonstrations:
- Behavioral Cloning: Copying observed behavior. Lecture 2
- Inverse RL: Inferring rewards from observed behavior. Lecture 15
From environment observations:
- Standard DRL: Learn best action for each state by interacting with the environment. Lecture 5, 6, 7, 8, 9
- Model Learning: Learn a model of the environment to then find an optimal policy. Lecture 10, 11, 12
- Unsupervised Learning: Observe the environment and extract features.
From other tasks:
- Transfer Learning: Share knowledge between different tasks Lecture 16
- Meta-learning: Learning to learn: Use past learned tasks to optimize the learning process. Lecture 20
How to build intelligent machines:
- Classic engineering approach: Split problem into easier sub-problems, solve them independently and wire them together.
- Problems:
- Sub-problems in intelligent systems can already be too complex.
- Wiring of non-intentional abstracted blocks may rise issues.
- Problems:
- Learning-based approach: Use learning as a base for intelligence.
- Motivations:
- While some human behaviors may be innate (walking), others can only be learned (driving a car is clearly not programed into us by evolution) $\Rightarrow$ humans have learning mechanisms powerful enough to perform everything associated with intelligence.
- Problems:
- Still might be convenient to hard-code some bits.
- Doubts:
- Should we still split the problem into sub-domains and apply different learning algorithms to each one (e.g. one for perception, one for locomotion…) or use a single learning algorithm which acquires the functionality of these subdomains? There is some evidence supporting a single learning method:
- Resemblance between features extracted by Deep Neural Nets (DNN) and primary cortical receptive fields. Andrew Saxe et al.
- Re-wiring optical nerve to auditory cortex. This experiment shows how a mammal can re-learn to process its eyes visual information using its auditory cortex.
- With BrainPort device you can “see through your tongue”. It converts images into electric signals perceived by the tongue.
- Should we still split the problem into sub-domains and apply different learning algorithms to each one (e.g. one for perception, one for locomotion…) or use a single learning algorithm which acquires the functionality of these subdomains? There is some evidence supporting a single learning method:
- Motivations:
State of the art:
What can DRL do well?
- High proficiency in domains with simple and known rules: AlphaGo, Atari Games
- Learn simple skills with raw sensory inputs (given enough experience) Sergey Levine Research
- Learn by imitating enough human expert behavior
What are main DRL challenges?
- DRL methods are very slow: They require a lot of experience samples before they work well.
- Humans re-use a lot of knowledge but transfer learning in DRL is still an open problem.
- How should the reward function be? What is the role of predictions?